
Learn how to build Llama 3.2-Vision locally in a chat-like mode, and explore its Multimodal skills on a Colab notebook

The integration of vision capabilities with Large Language Models (LLMs) is revolutionizing the computer vision field through multimodal LLMs (MLLM). These models combine text and visual inputs, showing impressive abilities in image understanding and reasoning. While these models were previously accessible only via APIs, recent open source options now allow for local execution, making them more appealing for production environments.
In this tutorial, we will learn how to chat with our images using the open source Llama 3.2-Vision model, and you’ll be amazed by its OCR, image understanding, and reasoning capabilities. All the code is conveniently provided in a handy Colab notebook.
Background
Llama, short for “Large Language Model Meta AI” is a series of advanced LLMs developed by Meta. Their latest, Llama 3.2, was introduced with advanced vision capabilities. The vision variant comes in two sizes: 11B and 90B parameters, enabling inference on edge devices. With a context window of up to 128k tokens and support for high resolution images up to 1120×1120 pixels, Llama 3.2 can process complex visual and textual information.
Architecture
The Llama series of models are decoder-only Transformers. Llama 3.2-Vision is built on top of a pre-trained Llama 3.1 text-only model. It utilizes a standard, dense auto-regressive Transformer architecture, that does not deviate significantly from its predecessors, Llama and Llama 2.
To support visual tasks, Llama 3.2 extracts image representation vectors using a pre-trained vision encoder (ViT-H/14), and integrates these representations into the frozen language model using a vision adapter. The adapter consists of a series of cross-attention layers that allow the model to focus on specific parts of the image that correspond to the text being processed [1].
The adapter is trained on text-image pairs to align image representations with language representations. During adapter training, the parameters of the image encoder are updated, while the language model parameters remain frozen to preserve existing language capabilities.
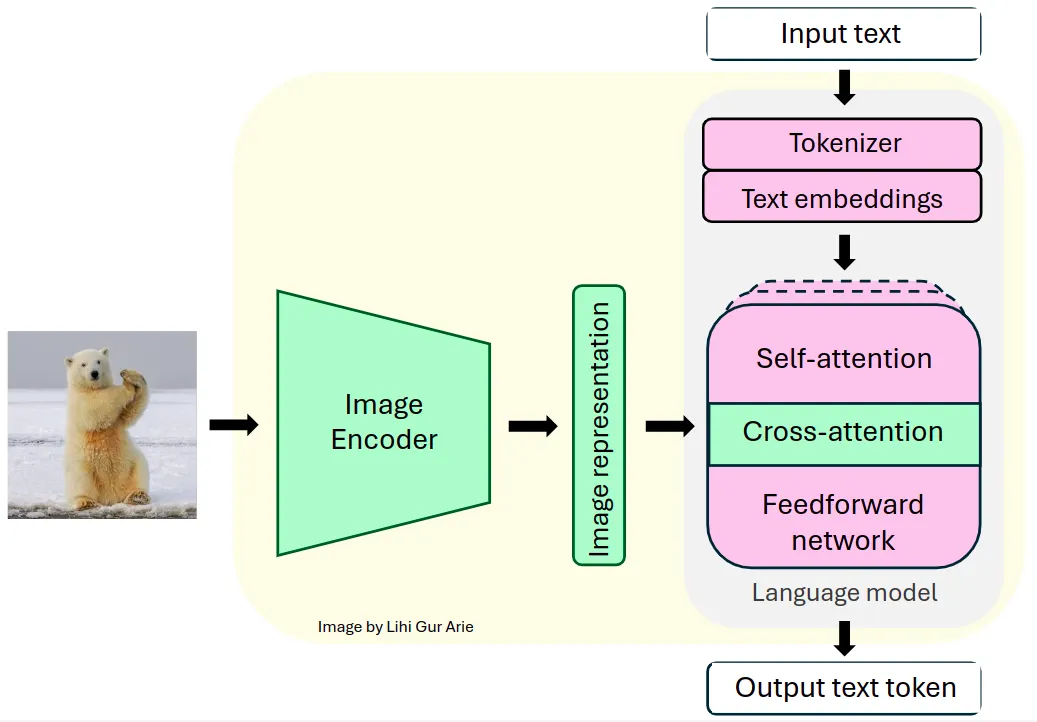
This design allows Llama 3.2 to excel in multimodal tasks while maintaining its strong text-only performance. The resulting model demonstrates impressive capabilities in tasks that require both image and language understanding, and allowing users to interactively communicate with their visual inputs.
With our understanding of Llama 3.2’s architecture in place, we can dive into the practical implementation. But first, we need do some preparations.
Preparations
Before running Llama 3.2 — Vision 11B on Google Colab, we need to make some preparations:
- GPU setup:
- A high-end GPU with at least 22GB VRAM is recommended for efficient inference [2].
- For Google Colab users: Navigate to ‘Runtime’ > ‘Change runtime type’ > ‘A100 GPU’. Note that high-end GPU’s may not be available for free Colab users.
2. Model Permissions:
- Request Access to Llama 3.2 Models here.
3. Hugging Face Setup:
- Create a Hugging Face account if you don’t have on already here.
- Generate an access token from your Hugging Face account if you don’t have one, here.
- For Google Colab users, set up the Hugging Face token as a secret environmental variable named ‘HF_TOKEN’ in google Colab Secrets.
4. Install the required libraries.
Loading The Model
Once we’ve set up the environment and acquired the necessary permissions, we will use the Hugging Face Transformers library to instantiate the model and its associated processor. The processor is responsible for preparing inputs for the model and formatting its outputs.
model_id = "meta-llama/Llama-3.2-11B-Vision-Instruct"
model = MllamaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto")
processor = AutoProcessor.from_pretrained(model_id)
Expected Chat Template
Chat templates maintain context through conversation history by storing exchanges between the “user” (us) and the “assistant” (the AI model). The conversation history is structured as a list of dictionaries called messages, where each dictionary represents a single conversational turn, including both user and model responses. User turns can include image-text or text-only inputs, with {"type": "image"} indicating an image input.
For example, after a few chat iterations, the messages list might look like this:
messages = [
{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": prompt1}]},
{"role": "assistant", "content": [{"type": "text", "text": generated_texts1}]},
{"role": "user", "content": [{"type": "text", "text": prompt2}]},
{"role": "assistant", "content": [{"type": "text", "text": generated_texts2}]},
{"role": "user", "content": [{"type": "text", "text": prompt3}]},
{"role": "assistant", "content": [{"type": "text", "text": generated_texts3}]}
]
This list of messages is later passed to the apply_chat_template() method to convert the conversation into a single tokenizable string in the format that the model expects.
Main function
For this tutorial I provided a chat_with_mllm function that enables dynamic conversation with the Llama 3.2 MLLM. This function handles image loading, pre-processes both images and the text inputs, generates model responses, and manages the conversation history to enable chat-mode interactions.
def chat_with_mllm (model, processor, prompt, images_path=[],do_sample=False, temperature=0.1, show_image=False, max_new_tokens=512, messages=[], images=[]):
# Ensure list:
if not isinstance(images_path, list):
images_path = [images_path]
# Load images
if len (images)==0 and len (images_path)>0:
for image_path in tqdm (images_path):
image = load_image(image_path)
images.append (image)
if show_image:
display ( image )
# If starting a new conversation about an image
if len (messages)==0:
messages = [{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": prompt}]}]
# If continuing conversation on the image
else:
messages.append ({"role": "user", "content": [{"type": "text", "text": prompt}]})
# process input data
text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(images=images, text=text, return_tensors="pt", ).to(model.device)
# Generate response
generation_args = {"max_new_tokens": max_new_tokens, "do_sample": True}
if do_sample:
generation_args["temperature"] = temperature
generate_ids = model.generate(**inputs,**generation_args)
generate_ids = generate_ids[:, inputs['input_ids'].shape[1]:-1]
generated_texts = processor.decode(generate_ids[0], clean_up_tokenization_spaces=False)
# Append the model's response to the conversation history
messages.append ({"role": "assistant", "content": [ {"type": "text", "text": generated_texts}]})
return generated_texts, messages, images
Chat with Llama
- Butterfly Image Example
In our our first example, we’ll chat with Llama 3.2 about an image of a hatching butterfly. Since Llama 3.2-Vision does not support prompting with system prompts when using images, we will append instructions directly to the user prompt to guide the model’s responses. By setting do_sample=True and temperature=0.2 , we enable slight randomness while maintaining response coherence. For fixed answer, you can set do_sample==False . The messages parameter, which holds the chat history, is initially empty, as in the images parameter.
instructions = "Respond concisely in one sentence."
prompt = instructions + "Describe the image."
response, messages,images= chat_with_mllm ( model, processor, prompt,
images_path=[img_path],
do_sample=True,
temperature=0.2,
show_image=True,
messages=[],
images=[])
# Output: "The image depicts a butterfly emerging from its chrysalis,
# with a row of chrysalises hanging from a branch above it."

As we can see, the output is accurate and concise, demonstrating that the model effectively understood the image.
For the next chat iteration, we’ll pass a new prompt along with the chat history (history) and the image file (images). The new prompt is designed to assess the reasoning ability of Llama 3.2:
prompt = instructions + "What would happen to the chrysalis in the near future?"
response, messages, images= chat_with_mllm ( model, processor, prompt,
images_path=[img_path,],
do_sample=True,
temperature=0.2,
show_image=False,
messages=messages,
images=images)
# Output: "The chrysalis will eventually hatch into a butterfly."
We continued this chat in the provided Colab notebook and obtained the following conversation:

The conversation highlights the model’s image understanding ability by accurately describing the scene. It also demonstrates its reasoning skills by logically connecting information to correctly conclude what will happen to the chrysalis and explaining why some are brown while others are green.
2. Meme Image Example
In this example, I will show the model a meme I created myself, to assess Llama’s OCR capabilities and determine whether it understands my sense of humor.
instructions = "You are a computer vision engineer with sense of humor."
prompt = instructions + "Can you explain this meme to me?"
response, messages,images= chat_with_mllm ( model, processor, prompt,
images_path=[img_path,],
do_sample=True,
temperature=0.5,
show_image=True,
messages=[],
images=[])
This is the input meme:

And this is the model’s response:

As we can see, the model demonstrates great OCR abilities, and understands the meaning of the text in the image. As for its sense of humor — what do you think, did it get it? Did you get it? Maybe I should work on my sense of humor too!
In this tutorial, we learned how to build the Llama 3.2-Vision model locally and manage conversation history for chat-like interactions, enhancing user engagement. We explored Llama 3.2’s zero-shot abilities and were impressed by its scene understanding, reasoning and OCR skills.
Advanced techniques can be applied to Llama 3.2, such as fine-tuning on unique data, or using retrieval-augmented generation (RAG) to ground predictions and reduce hallucinations.
Overall, this tutorial provides insight into the rapidly evolving field of Multimodal LLMs and their powerful capabilities for various applications.
Congratulations on making it all the way here. Click  x50 to show your appreciation and raise the algorithm self esteem
x50 to show your appreciation and raise the algorithm self esteem 
Want to learn more?
[0] Code on Colab Notebook: link
[1] The Llama 3 Herd of Models
[2] Llama 3.2 11B Vision Requirements
from Artificial Intelligence – Techyrack Hub https://ift.tt/np8qo6w
via IFTTT
0 Comments